
H∞P Challenge Lab: Social Impact & M&E
Practical exercises for governing AI-assisted evidence, reporting, and evaluation workflows.
For people handling field evidence, community testimony, grievance material, and reports that cannot afford synthetic certainty.
Global development and impact evaluators are feeding qualitative field data, community interviews, and M&E reports into commercial AI. Without governance, this accelerates erasure of nuance and outsources moral judgment. Assistance earns its place when the workflow preserves context and stop-work authority, with attribution intact.
From liability to contractual durability.
The sequence moves from stop-work authority to observation, verification, output integrity, architectural friction, and contract language.
- M01Diagnose the problemLiability sponge
- M02Notice the seamSpeed inversion
- M03Verify comprehensionLive-edit test
- M04Evaluate outputsVictim Register
- M05Build the missing signalInterface of conscience
- M06Embed in contractsAudit trail
Follow the sequence, or open the pressure point you recognise.
Each exercise turns a common failure pattern into a practical review method, conversation script, or governance template.
01The Liability Sponge in Social ResearchAI summaries may be wrong, but junior staff often carry responsibility for outputs they did not verify, tools they did not procure, and timeframes they did not set.
Participants map where responsibility is pushed onto reviewers, analysts, associates, or field teams without giving them evidence access or authority to stop.
The module turns vague accountability anxiety into a visible workflow map: who enters data, who prompts, who checks, who signs, and who gets blamed.
02Reading the Rhythm: Speed Inversion & Generous SuspicionThe seam often appears in rhythm before it appears in evidence: instant polished artifacts paired with slow, thin, or evasive process explanation.
This module teaches detection without accusation. Teams learn to treat odd rhythm as a calibration signal, then ask for process evidence in a way that protects trust.
Generous suspicion sounds like: walk me through how you approached it, including any tools or support you used.
- Technical-communicative split: instant artifact, slow explanation.
- Creative-analytical inversion: polished ideation, sticky follow-through.
- Synchronous-asynchronous gap: fluent async work, weaker live navigation.
- Vanishing revision trail: work arrives born, not built.
03The Live-Edit Test: From Artifact to AgencyProduction can be proxied by machines; navigation cannot. The question is whether the person can inhabit, revise, and defend the work.
Participants practise short live-edit protocols for research synthesis, survey analysis, field-note summaries, and stakeholder reports.
The test is framed as collaborative comprehension, not a trap. It reveals whether the work is owned well enough to be changed under shared attention.
- Use a five-minute edit window.
- Watch for defense tax: how much effort is spent explaining why change is impossible.
- Ask for reasoning, trade-offs, and source handling while changing one small thing.
04The Victim RegisterPolite AI can dilute the severity of community grievances. The report must be defensible to the people described, not only to the client receiving it.
Participants review outputs from the position of the downstream person who pays if the output is wrong, smoothed, or incomplete.
The method keeps harm, uncertainty, dissent, and evidence gaps visible even when the final report needs to be concise.
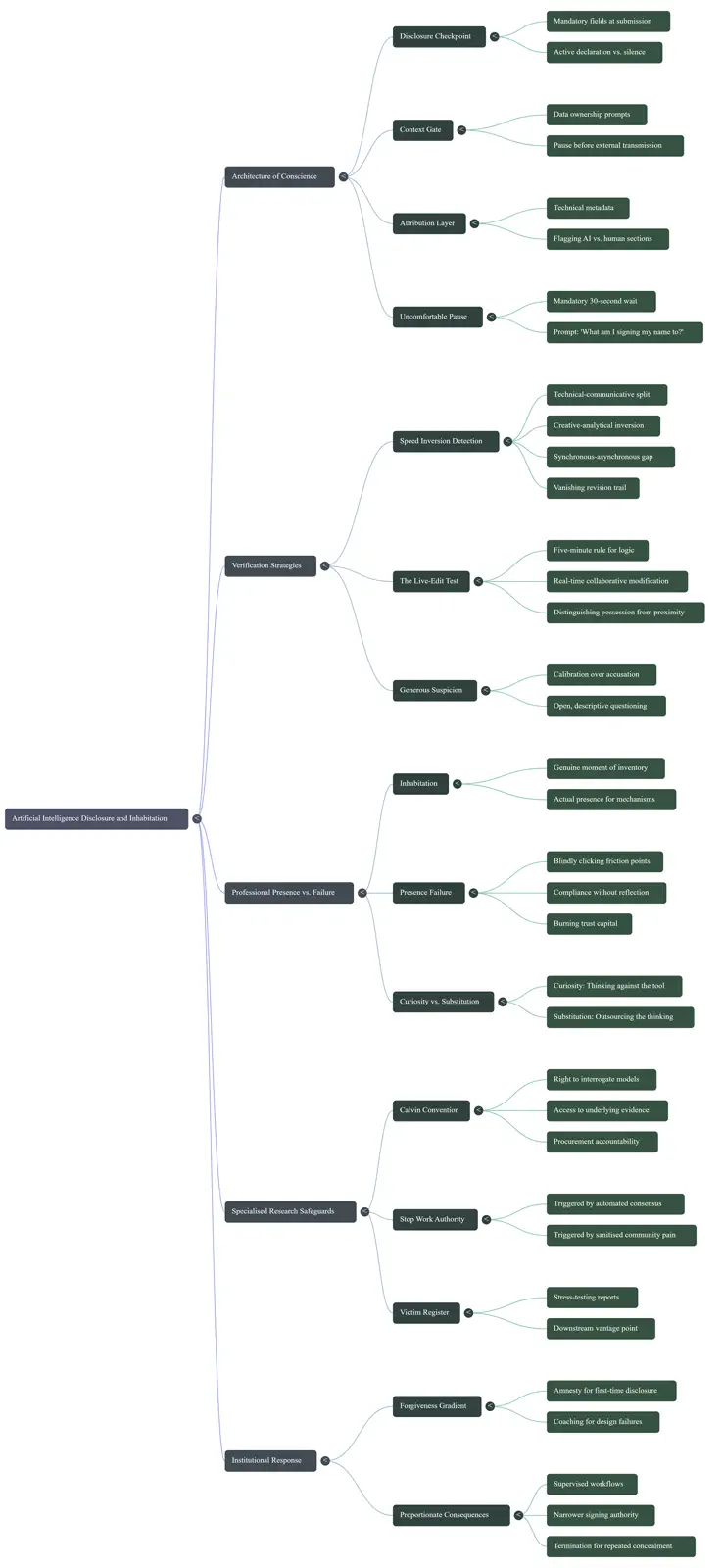
05The Interface of ConscienceConscience has to live in the machinery. If disclosure, context, attribution, and pause are optional, the workflow will forget them when pressure rises.
This module turns ethical unease into four specific friction points that can be placed inside research, reporting, and approval workflows.
The aim is not performative caution. It is a designed moment where a person has enough signal to decide what they are signing their name to.
- Disclosure Checkpoint: AI assistance yes, no, or partially.
- Context Gate: who owns this data, and is it covered by confidentiality or data-sovereignty obligations?
- Attribution Layer: metadata marks AI, human, and collaborative sections.
- Uncomfortable Pause: a short wait before significant submission, asking what am I signing my name to?
06The Audit Trail: Vendors, Associates, HiresThe method has to survive procurement, subcontracting, hiring, and delivery pressure, or it remains a workshop memory.
Participants translate the previous modules into vendor questions, associate contract language, recruitment policy, documentation discipline, and incident handling.
The emphasis is durability without scapegoating: make AI use documentable, discussable, and governable before something goes wrong.
M&E directors, ESG risk leads, field research managers, social-impact consultants, and teams overseeing high-stakes qualitative data pipelines.
Community resettlement grievances, qualitative M&E field notes, vendor-supplied dashboards, AI-assisted report drafting, associate research work, and subcontractor AI use.
A mapped liability audit, stop-work thresholds, calibration scripts, live-edit protocol, victim-register QA, four friction specs, Calvin Convention procurement clauses, and associate or recruitment addenda.
Quick checks for whether the method is needed.
A flawless summary of community interviews arrives in minutes, but nobody can explain the coding decisions. What should be checked first?
The issue is not only whether AI was used. It is whether the method can be reconstructed and defended.
A report removes angry language from grievance testimony because it sounds too subjective. What tool should be used?
The register asks who pays if the softened version becomes institutional truth.
A team says AI was only used for drafting, but the output contains untraceable claims. Which friction point is missing?
Sections need a visible account of whether they are human-authored, AI-assisted, or collaborative.
Continue from here
A compact visual version of the six-module sequence and its governance questions.
Audience, formats, advisory fit, and the practical shape of team training.
Use the intake form when there is a team, workflow, vendor, or deadline to scope.
Bring this H∞P Challenge Lab to a team.
Use the intake form to describe the workflow, tool, vendor, report, or deadline. That keeps enquiries structured before any follow-up.
Start the intake form